Version 4.3 of the DataCite Metadata Schema released during August, 2019 included (among other things), the capability to provide persistent identifiers for affiliated organizations in the metadata (Dasler and deSmaele, Identify your affiliation with Metadata Schema 4.3, 2019). This capability builds on the work and enthusiasm generated by the ROR Community that has championed the concept of open organization identifiers for several years (Gould, A Reflection on ROR’s First Year, 2019). This is a critical step towards consistent integration of organizations into the growing web of connections across the scholarly communications landscape and research communities in all disciplines.
The first organizational identifiers in DataCite metadata were funderIdentifiers introduced in Version 4.0 during late 2016. These identifiers might now be considered mature in DataCite metadata and will not be considered. Here we focus on organizational identifiers introduced last August and are integrated into the DataCite schema as affiliationIdentifiers associated with either creators or contributors. In this blog I identify the early adopters that have already started to build these important connections into their metadata.
Finding Early Adopters
The DataCite API makes it easy to find repositories that are adopting these new identifiers with two requests and a small bit of python (both functional but certainly could be improved):
Creators:
import requests
import json
#
# Query DataCite for records that contain affiliationIdentifiers for creators
#
URL = """https://api.datacite.org/dois?\
query=creators.affiliation.affiliationIdentifier:*\
&affiliation=true&page%5Bsize%5D=1"""
r = requests.get(URL)
for i in r.json()['meta']['clients']:
print(i['title'], i['id'], i['count'])
Contributors:
import requests
import json
#
# Query DataCite for records that contain affiliationIdentifiers for contributors
#
URL = """https://api.datacite.org/dois?\
query=contributors.affiliation.affiliationIdentifier:*\
&affiliation=true&page%5Bsize%5D=1"""
r = requests.get(URL)
for i in r.json()['meta']['clients']:
print(i['title'], i['id'], i['count'])
Note that both of these queries list only the fifteen repositories with the largest number of identifiers.
The results of these queries (as of 2020-02-17), shown in the Table below, indicate that identifiers for creators, in 15+ repositories, are currently more common than identifiers for contributors, in 8 repositories, and that three repositories (bl.imperial, bl.nerc, and tib.wdcc) currently have some identifiers of both types. The counts in this Table are numbers of records with affiliations, not the number of affiliations.
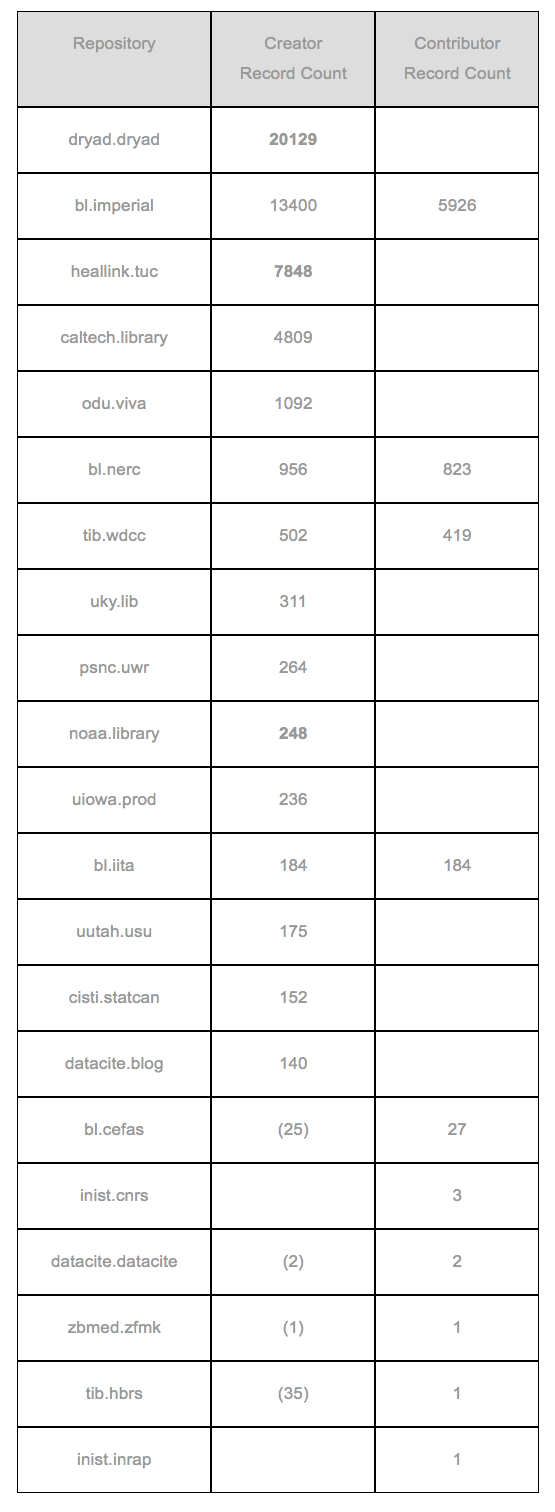
The numbers in this Table allow us to identify the early adopters of organizational identifiers, both DataCite members and repositories. These members of the community are the “guinea pigs” in this effort that are committed enough to the benefits of organizational identifiers in metadata to take action and serve as good examples for the community. All should be recognized as pioneers!
In an earlier blog (Habermann, How Many ROR’s Do We Need?, 2019) I made the somewhat surprising observation that many DataCite repositories contained only a small number of unique affiliations and, therefore, those repositories could uniquely identify all organizations in their metadata with a small number of organizational identifiers. These earlier data are shown in this Figure. It indicates that 108 repositories only need one ROR and that 235 need five or less. This is great news for the adoption of RORs.
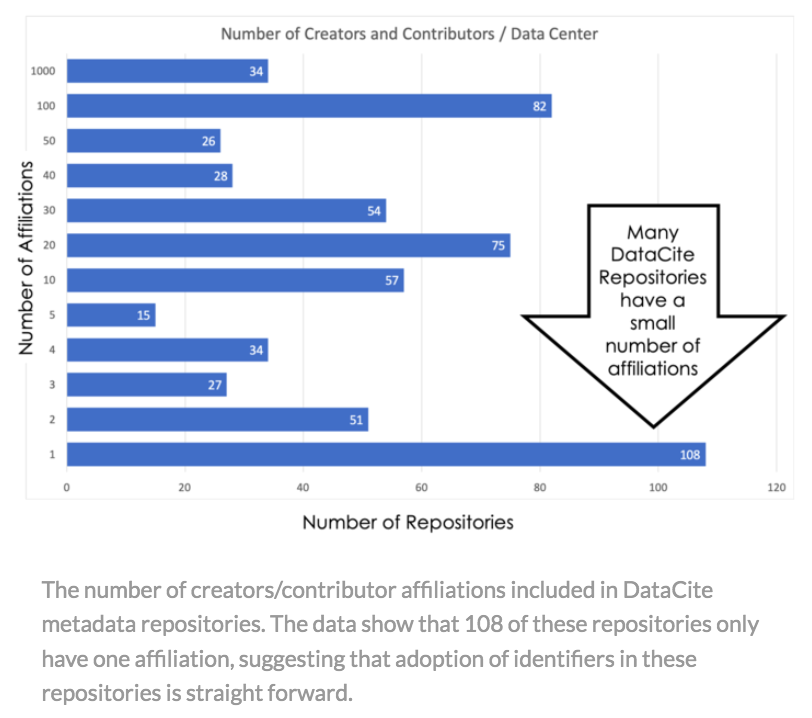
The early adopters identified above include examples where many metadata records contain a small number of affiliations – low hanging fruit along the path to adoption. Others face much more difficult tasks because of large numbers of affiliations spread across many records. We look forward to learning lessons as all of these groups forge forward.
Ted Habermann is a member of the ROR Community Advisory Group. He is currently the founder and CEO of Metadata Game Changers, working with communities to understand and improve how they use metadata to share data and knowledge. This has been re-posted from the Metadata Game Changers blog.
RSS Feed
Categories
Archives
Tags
- adoption
- annual-meeting
- api
- aps
- caltechdata
- clarivate
- clear-skies
- coki
- communication
- community
- cross-post
- crossref
- curation
- data
- datacite
- datasalon
- development
- dryad
- europepmc
- facilities
- fairsharing
- feedback
- figshare
- funders
- governance
- grei
- grid
- hierarchy
- implementation
- integrations
- interviews
- inveniordm
- jobs
- latin-america
- machine-learning
- matching
- metadata
- mvr
- open-access
- open-infrastructure
- openalex
- optica
- orcid
- osf
- persistent-identifiers
- pidapalooza
- pids
- prototype
- publishers
- publishing
- registry
- research-integrity
- researchequals
- resources
- rockefeller-university-press
- rrid
- schema
- scholastica
- silverchair
- steering-group
- straininfo
- sustainability
- team
- web-of-science
- working-group
- zenodo