In this case study we interview Tom Morrell, Research Data Specialist at Caltech Library and key contributor to the open source research data management system InvenioRDM, about Caltech’s early adoption of ROR IDs in their repository systems and why InvenioRDM is architected with ROR IDs for funders and author affiliations.
Key quotations
“Basically as soon as ROR came out and it was supported in DataCite, once they said, ‘We’ve got a spot in the metadata to put ROR,’ we pretty quickly implemented ROR for our thesis repository. That was a really easy, easy case, because we know everybody who has a thesis in the thesis repository is affiliated with Caltech.”
“We had an initial version of the data repository […] and in that one we didn’t have any affiliation identifiers. There was an affiliation field, but no identifier, because we implemented this before ROR existed, and we didn’t like any of the other identifiers that were available.”
“[InvenioRDM has] been built so that the bones assume that ROR exists, and that’s really nice, because we’ve got that open identifier baked into the software stack.”
“At the moment we don’t have to do a ton of reporting back to the funders to say what datasets were associated with a given grant, but we’re anticipating that we’re going to have to do that in the next few years, so having the ability to pull out exactly what records are associated with a given funder is going to be very important. We have it in the system now, so instead of just having people type in the text and the different variations of ‘National Institutes of Health’ or ‘National Science Foundation,’ instead, you have them type it in, it assigns the ROR to it, and then we’ll be able to pull records out via the ROR.”
– Tom Morrell, Research Data Specialist, Caltech Library
Amanda French
Thank you so much for joining me to talk about your ROR implementation. If you could, please start by telling us your name, title, and organization.
Tom Morrell
Hi, I’m Tom Morrell. I’m the Research Data Specialist at Caltech Library.
Amanda French
Perfect. Can you tell us about Caltech Library and the unit that you’re in?
Tom Morrell
Caltech Library serves all the information needs of Caltech as a campus. And Caltech is a kind of unique institution. We’re small in terms of numbers. We have about 300 faculty, but we have a really big impact in a lot of research areas – in Astronomy, Astrophysics, Biology, Neuroscience. We’ve got a lot of high-impact work, just done with a very small staff. So what the library does is we serve everybody on campus. We serve traditional library information needs in terms of journals, for instance, but we also have a very strong repository program in terms of making the research content of Caltech publicly available. That includes publications (CaltechAUTHORS) and theses (CaltechTHESIS) as well as what I spend most of my time working on, which is datasets and research software (CaltechDATA).
Amanda French
And when did when did Caltech first start its repositories? You have both an institutional repository and a data repository, correct?
Tom Morrell
I don’t remember off the top my head the original date. We were very early. We were part of some of the initial discussions up at Los Alamos about the concept of institutional repositories and making content open. We have over 100,000 items in our main institutional repository, which, as a percentage of the output of the institution is very, very high, so we’ve got lots of dedicated librarians who’ve put a lot of effort into collecting content and writing up quality metadata for the content and making that publicly available. And one of the things that I really enjoy being able to do is to figure out ways of making that content more discoverable and more valuable, using things like ROR.
Amanda French
Wonderful. So where and when did you personally first hear about ROR?
Tom Morrell
Oh, that’s a good question. It was probably at one of the conferences very early on, when ROR was just beginning, and it was likely in the context of DataCite metadata. That’s where I’ve spent a lot of my time, is figuring out how we can best describe things like our datasets and software in DataCite metadata. And one of the challenges always was, you know, How do we do affiliations? And before ROR there wasn’t really an easy, open way of saying “This the affiliation that I mean.” So when I heard of ROR, I was like, “This is really just the perfect solution for how we handle affiliations and identifying where people are coming from.”
Amanda French
Were you the primary advocate of implementing ROR at your organization?
Tom Morrell
I would say yes, but we had lots of other librarians who were also very excited and interested in this. Because it’s going to be helpful not only for discoverability by making our metadata better, but it’ll also be really helpful for reporting. One of the types of reports that we have to do often is compliance reports for funders, and we track who’s collaborating with who. At the moment those are challenging to put together, because you need to know everybody’s affiliation, and trying to match up what a given affiliation is when you have random strings that are coming in from publications is really challenging. So we have librarians who are very excited about the possibility of actually having identifiers for these affiliations. That makes a lot of the reporting stuff a lot easier.
Amanda French
And just to clarify your role: are you responsible primarily for the data repository, or do you also have a role on the institutional repository?
Tom Morrell
My primary role is the data repository, but I also help out with the institutional repository as well on the technical end. We’re currently in the process of migrating the institutional repository (CaltechAUTHORS) to InvenioRDM, so I’m leading the group that’s doing that migration.
Amanda French
That’s actually very exciting.
Tom Morrell
So yeah, I kind of am the bridge. We have research services librarians who work with the researchers and make all the decisions for the institutional repository: How should we describe these articles? How should we tag and organize and collect them? And they enter them into the system. Where I come in is more on the technical end: How should we actually manage the metadata? How can we do bulk updates to the institutional repository? And then we’ve got software developers in the Digital Library Development group that do more of the you know, nuts and bolts of really doing the software development. So I’m kind of in an intermediate role between the librarians and the software developers.
Amanda French
Gotcha. So your thesis repository, I believe, currently runs on EPrints, and your data repository runs on InvenioRDM, and you have ROR integrated into both right now?
Tom Morrell
Yes, we do. I’ll run through the history of how we did the integration. Basically as soon as ROR came out and it was supported in DataCite, once they said, “We’ve got a spot in the metadata to put ROR,” we pretty quickly implemented ROR for our thesis repository. That was a really easy, easy case, because we know everybody who has a thesis in the thesis repository is affiliated with Caltech. [Note: For an interesting analysis of affiliations in university repositories, see Habermann, T. (2022, June 24). Universities@DataCite. Metadata Game Changers blog.]
Amanda French
It’s one single ROR ID!
Tom Morrell
It’s one single ROR ID. And for the DOI minting, we were not particularly happy with the built-in plugin. EPrints generally, we’ve used it for a very long time, and it’s been a great system, but it is definitely showing its age. So we started doing some of our development work outside of EPrints, because that allows us to be much faster and more efficient than writing things in Perl. So the way we do our DOI minting for the theses, we basically have an external script that pulls out the metadata, reformats it, and then mints the DOI. So we were able to pretty easily add ROR IDs for the theses. Each thesis has an author name, and then we put in the affiliation with the ROR ID. And then we went through and then bulk updated all of the DOIs with the new affiliation and ROR ID. That was our first implementation, and it was very straightforward because we knew what the ROR should be, we knew where it would go, and we had the tooling to basically automatically add it.
Amanda French
About how many theses do you think that was, that you added the ROR to in the DOI? Do you know, roughly?
Tom Morrell
It was approximately 10,000 theses.
Amanda French
Fantastic. I’m gonna ask you a very random question now, and there’s no shame if you answer it in the negative. Do you by any chance have the ROR ID for Caltech memorized?
Tom Morrell
I have about the first 3 characters. I don’t have the full one memorized.
Amanda French
It’s meant to be random, so I’m not surprised, but I just wondered, since you’ve had so much experience with that particular ROR ID. So that’s ROR in CaltechTHESIS. Tell us about the data repository and InvenioRDM. How did you decide on that system? And tell us about ROR in that system. [Note: CaltechDATA on InvenioRDM launched in September 2022.]
Tom Morrell
When we were looking at the data repository we wanted a system that was open source, but also one where it was really easy for researchers to do their own deposits. In comparison to the institutional repository where you get the publication, and you can look at it and say “This the title, and these are the authors” and so forth, we have a random data file. You really need the researcher to be involved in the process of describing what the dataset is and what papers it’s connected to. So we wanted to make sure the researcher had a very easy and straightforward way of making a submission to the repository, and one of the things that we liked about Invenio and InvenioRDM is it’s based on the really successful open repository Zenodo, which has gotten a lot of traction, because it’s very easy to go upload your dataset and get them DOIs and get them preserved in a way that other people can access them. So we really like the ease of use, and we like that it’s an open source project, and we like that it was written in Python, so it’s easy for us to do additional development and make additional contributions to the community. And one of the exciting things for us about InvenioRDM has been to see how the community has grown over the last couple of years. We were one of the first members in the group, and it’s now got lots of new people joining and working on rolling out their own repositories for their own institutions. So from a technical side, it’s nice to be able to make contributions into a codebase that then a lot of other people are going to use.
It’s very exciting that that’s public now and that we’ve got a more firm timeline for it. There’s a lot of nice harmonization if folks are working together on a project. It makes everything more efficient.
Amanda French
So my understanding is that InvenioRDM has ROR basically already built into every part of it. Did you have to do any additional customization to it?
Tom Morrell
Yes. I’ll talk about our migration process. There’s what we did with our data, and then there’s what we hope to be able to do in the future with InvenioRDM. We had an initial version of the data repository which was on another version of Invenio, and in that one we didn’t have any affiliation identifiers. There was an affiliation field, but no identifier, because we implemented this before ROR existed, and we didn’t like any of the other identifiers that were available. So as part of the migration, we wanted to start to add RORs into the existing affiliations that we had. And librarian Kathy Johnson did a great job. We used the RORRetriever from Metadata Game Changers.
Amanda French
Ah, yes.
Tom Morrell
We used that little automation to take all of the strings that we had for affiliations and make a guess as to what the ROR might be. And then Kathy went through and verified whether that was correct or not. So we did kind of a minimal set of data enhancements, finding RORs for our existing records.
The migration script for CaltechDATA, which includes a lot of ROR mapping, is available on GitHub.
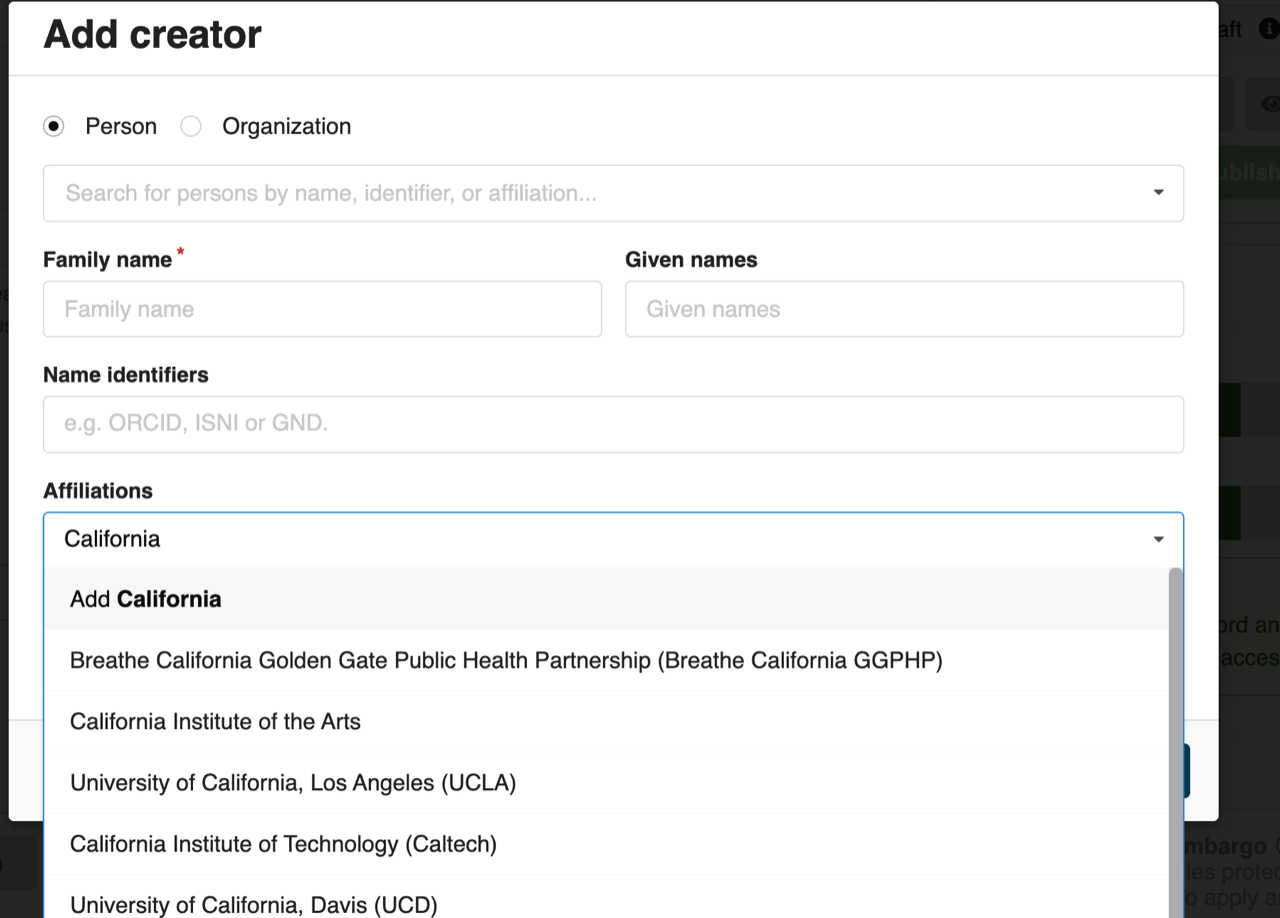
And then in the configuration of InvenioRDM, you can basically load in ROR for both the affiliation field, so all the affiliations, as well as for funders. So we’ve done that. When you go in to add an affiliation, it does a little search, and it’ll auto-complete based on ROR. And then similarly for the funders it will auto-complete the funder name and you can click which one you want. So that’s just out of the box configuration.
Entering an affiliation into CaltechDATA with InvenioRDM.
In terms of integration, we did some data cleanup, we configured InvenioRDM how it works out of the box, and that all is great. But we also have a lot of improvements that we want to do for the future that we hope we can contribute back, and things that the InvenioRDM community in general wants to work on. There’s being able to pull in the latest changes with inactive versus active RORs and have that show up in the interface, there’s having the country show up so we can get better disambiguation for organizations that have the same name, stuff like that. So there’s still a number of areas where I think we can improve InvenioRDM and how it handles RORs. But it’s been built so that the bones assume that ROR exists, and that’s really nice, because we’ve got that open identifier baked into the software stack.
Live stock - a cyclopedia for the farmer and stock owner, 1914, Internet Archive Book Images, No restrictions, via Wikimedia Commons.
Amanda French
Sounds great. It really is a terrific community, too, InvenioRDM. I lurk on the Discord, but I have not been hugely active in it.
Tom Morrell
The community is the best part of it.
Amanda French
That’s great. So can you tell me some of the benefits of having ROR in both the thesis repository system and the data repository system?
Tom Morrell
Yeah. In terms of the thesis repository, it’s allowed Caltech to be much more visible. If you do a search in DataCite for Caltech, you will get all of our theses, and it’ll pull up the disciplines and the tags. You just put it in the system, and it just works, because we’ve attached the ROR to all the affiliations. So in terms of accurately describing the output of the institution, it’s helped hugely in terms of just accurately saying, “This scholarly content has come from Caltech.”
In terms of the data repository, we’re still figuring out where it’s going to be useful in terms of reporting and cleanliness. One of the areas where it’s going to be very helpful is in terms of funders. At the moment we don’t have to do a ton of reporting back to the funders to say what datasets were associated with a given grant, but we’re anticipating that we’re going to have to do that in the next few years, so having the ability to pull out exactly what records are associated with a given funder is going to be very important. We have it in the system now, so instead of just having people type in the text and the different variations of “National Institutes of Health” or “National Science Foundation,” instead, you have them type it in, it assigns the ROR to it, and then we’ll be able to pull records out via the ROR. We don’t have as many specific use cases where we can say, “Yes, this is the reporting we’re using this for today,” but we’re anticipating it’s going to be really, really helpful, because there probably will be more compliance reporting we have to do.
Amanda French
Great. So what problems have you identified with ROR, if any? What do you wish ROR did that it isn’t currently doing?
Tom Morrell
One of the challenges we’ve found is in terms of what name shows up as the preferred name. Currently there is a little bit of variability as to what name is the main name for an organization versus other names. Particularly for international organizations, you know: Is the English name the one that shows up in the preferred name, or is it the Spanish name that shows up in the preferred name? We’ve run into some of that when we were doing some of the cleanup work, figuring out which ROR is really the right one for a given affiliation. And that’s something that also comes up in InvenioRDM when we’re going back and looking at old records where we have just affiliation strings. We have to make a decision. Do we go with the name that is associated with the ROR or do we leave the name that somebody typed in? There’s a decision point.
Amanda French
Right.
Tom Morrell
How do we respect the data that the user entered in, which might not be the cleanest or in the right form that we want, but also not change the way the name is shown? That’s something that we’re still working through, how we make decisions about how the name shows up in the system and on the specific records.
Amanda French
Oh, that’s interesting. Most ROR records have a lot of different names in different fields. There is the primary name, which, because we inherited it from GRID, tends to be in English. I’m not sure if they had that as a policy or if that was just their practice. But we definitely don’t have that policy, so we’ve been taking lots and lots of requests from international organizations to have the primary name in the name field be in the primary language of the country where that institution is located, when that is not English. But yeah, that’s interesting. And I’m sure you’ve seen our schema change proposals. We have lots and lots of proposed name-related changes.
Tom Morrell
Yeah, you’re all working on it, so it’s not like I’m worried about this at all. I think you’ve got it all under control. But that is an area where we did experience some challenges in terms of the data. And we have some general challenges with InvenioRDM in figuring out how we do the display of things.
Amanda French
Yeah, and even then, I’m not sure what we could do to help with that display issue, really.
Tom Morrell
No. It’s on our end to figure out how we want to handle that.
Amanda French
Interesting. I think that’s about all I have for you. What else do you want to tell us about the data repository, or the thesis repository, or your integrations of ROR generally?
Tom Morrell
I don’t know if I have anything else. I’m a big supporter of ROR, and I’ve been really thrilled to see how it’s evolved, particularly over the last couple of years. I feel like ROR has really gotten into its stride in terms of how it’s managing the curation process, making the data available, providing both useful data dumps and API features. I think it’s going to be a really powerful tool for allowing us to do all sorts of queries and identifying how people are associated with organizations and funders.
Amanda French
Great! That’s great to hear. Thank you so much, Tom.
Tom Morrell
Well, thank you. It’s been great to chat.
Questions? Want to be featured in a ROR case study? Contact community@ror.org.



.jpg){kind=link}