Case Study: ROR at Rockefeller University Press and Silverchair
By Amanda French | March 20, 2023
Rockefeller University Press has incorporated ROR into many aspects of their workflow, and their platform provider Silverchair was there to help. This case study is based on the presentation about this integration given at the December 2022 ROR Community Call by Rob O’Donnell, Senior Director of Publishing at RUP, and Emily Hazzard, Product Operations Analyst at Silverchair.
Key quotations
“When we get new deals, we set them up in eJournal Press systems. They’re configured using ROR IDs, and the process is then completely driven by ROR. The system looks for a match between affiliation ROR IDs and deal ROR IDs. And once there’s a match, we know the article is eligible for that deal.”
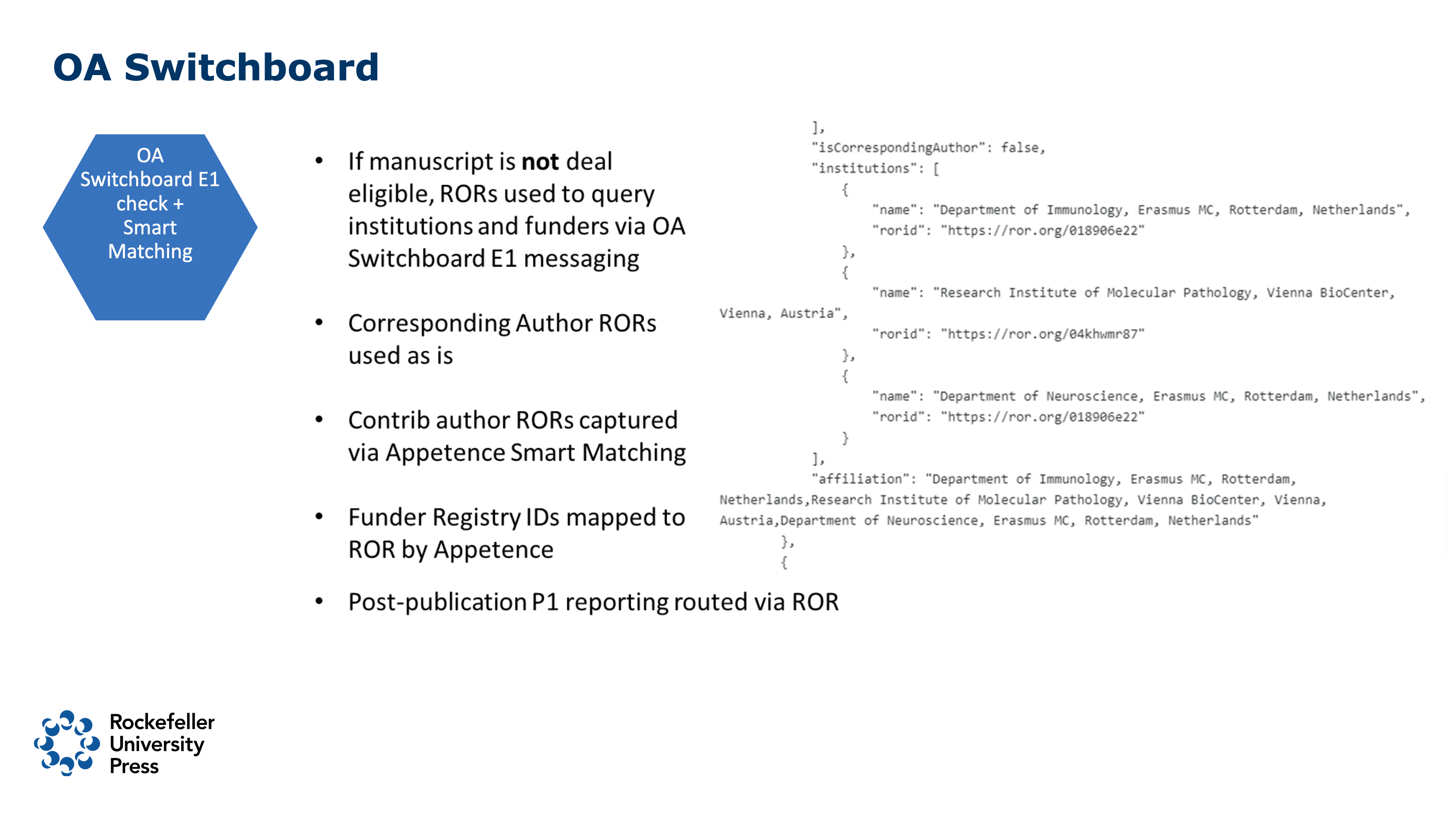
“I’m excited that we’re now live with our Open Access Switchboard eligibility workflow, which is known as “E1” in Switchboard lingo. If a manuscript is not recognized as part of a deal using what was shown in the last step, we use the ROR IDs we’ve gathered to sequentially query each of those organizations to ask if they’ll pay the gold OA fee for the article.”
“We include ROR IDs in our JATS files, and after an article is published, Silverchair includes those IDs in Crossref deposits.”
– Rob O’Donnell, Senior Director of Publishing, Rockefeller University Press
“In the institutional management service in SiteManager, we’re going to be introducing a way to search institutions based on the ROR ID because it’s incredibly convenient.”
“Something else that we’re planning on doing is introducing ROR-based reporting to support those Read and Publish agreements so that we can expose the relationships between those authors and institutions, and really see what’s coming out of these institutions. Where is it published? Where does it live? And how do we serve those authors better?”
We’ve asked Rob O’Donnell, Senior Director of Publishing at Rockefeller University Press, to tell us about some of the new things they’re doing with ROR.
Rob O’Donnell
Thanks for having me. Let me start by giving some pertinent information about Rockefeller University Press (RUP). We’re a small university press publishing 3 and 1/3 biomedical journals. The one-third is Life Science Alliance, which is a collaboration open access journal with Cold Spring Harbor Laboratory Press and EMBO Press. We’re predominantly institutional subscription based, transformative, and we’re using Read and Publish deals as a stepping stone on our way to becoming fully open access. We use eJournalPress (EJP) submission, production, and billing systems. Our content is hosted mostly on Silverchair; LSA’s content is on HighWire. We’re active with the OA Switchboard, which is a metadata exchange hub for both reporting and eligibility querying.
Rob O’Donnell
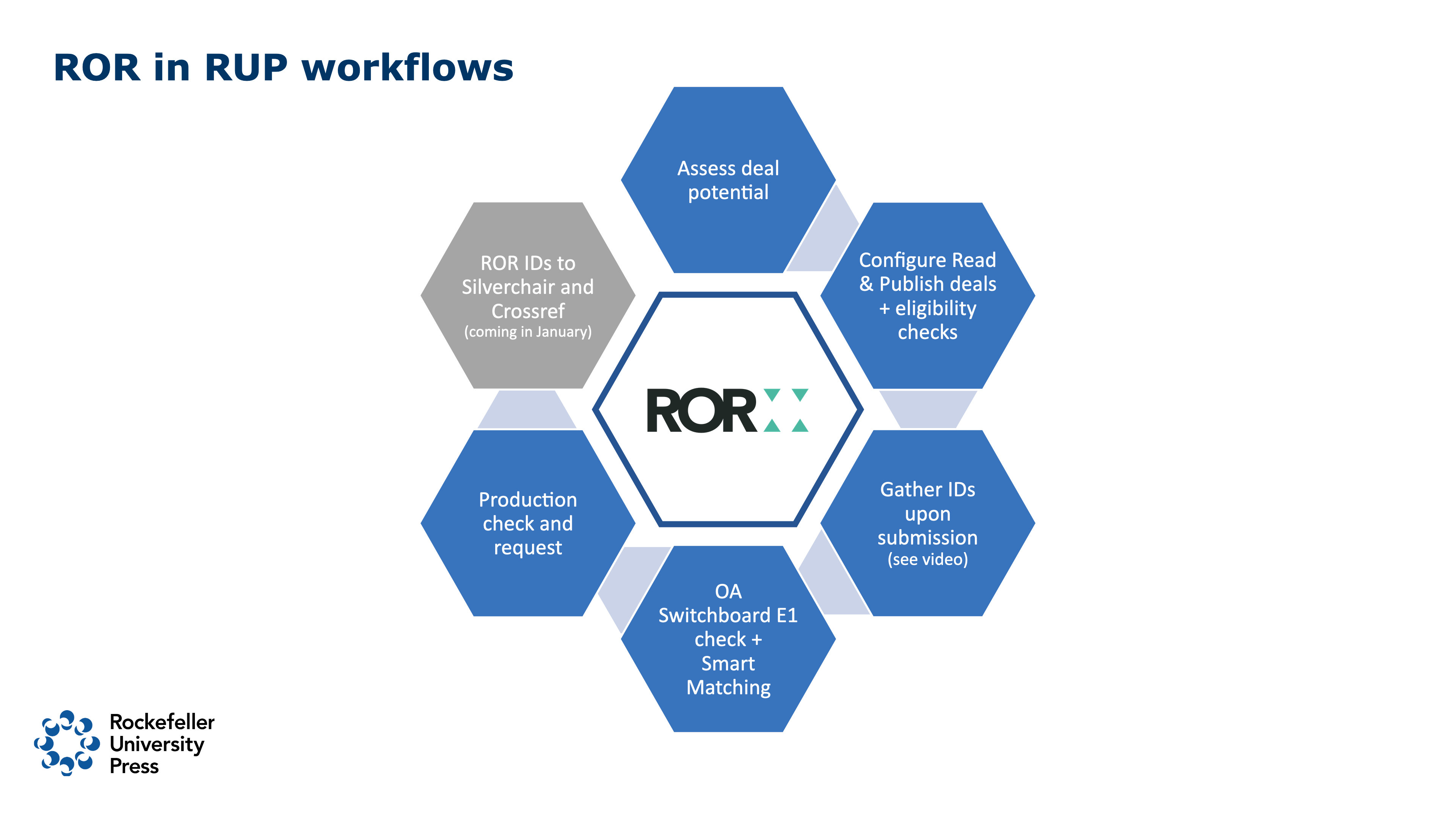
This slide is basically an outline of what I’m going to talk about, and I think it’s a good visual that shows how much our workflows now revolve around ROR. We’re using them really in every aspect of our workflow. I’ll start at the top with how we use ROR IDs to model our Read and Publish deals and then work clockwise.
Rob O’Donnell
We have Read and Publish deals with over 300 institutions across all our deals (totaling >600 ROR IDs). Now that includes consortia, but that’s the number of institutions we have so far. To get started, our Institutional Sales Manager, Miguel Peralta, mapped our subscriber IDs to ROR IDs. We already had Ringgold for most of our subscribers, so we started there and we went from Ringgold to ISNI to ROR. We also added those ROR IDs to our subscriber records in Silverchair’s SiteManager, and Emily will talk more about that later. Then we mapped archival author affiliations to ROR; we went back to 2017. Most of that mapping was done via Dimensions. We have a subscription to Dimensions, and Dimensions still includes GRID IDs in their results – not sure if they will update those to ROR IDs. They still use GRID internally, which made it easy to go from GRID to ROR. Once we had ROR IDs for both authors and subscribers, we were able to match our published output with subscribers in order to model and create our deal proposals. We also use the mapped ROR IDs to alert previous authors at deal institutions that they can now publish at no cost to them.
Rob O’Donnell
When we get new deals, we set them up in eJournal Press systems. They’re configured using ROR IDs, and the process is then completely driven by ROR. The system looks for a match between affiliation ROR IDs and deal ROR IDs. And once there’s a match, we know the article is eligible for that deal. Because we have consortia and large institutions, we need to map all sub-organizations that are included in deals as well, and this is a manual process. I’ve been wondering whether the IP Registry / PSI Registry could help here. They now have ROR IDs in the registry. We use PSI and they have our subscribers broken down and clustered into consortia or large institutions with only the sub-institutions as included in our subscriptions or deals. If those ROR IDs were included in the PSI API, it could be a huge help. When there is a match, the corresponding author is alerted that they’re eligible for a deal when they proceed to sign their license form. We are currently building other steps in the workflow to alert them earlier in the process.
Rob O’Donnell
When we first implemented this workflow we were only collecting ROR IDs for the corresponding author’s current address, which was a problem because that’s not necessarily a manuscript affiliation. Since then we’ve improved the process, and I show that in this short video. EJP has its own instance of the ROR database in their system. When the author is filling out their submission and starts typing the institution name the typeahead is looking up the ROR record in the EJP database. The author chooses the correct institution from the results list and is then presented with a green checkmark next to the institution name, an indication that it has been validated. We also have a new section asking the corresponding author for all of their affiliations. It’s the same process as just described for each affiliation. The video shows what happens if the author does not select from the typeahead menu, and they just hit Save, or if they choose a name that’s not in ROR – they get this message that basically says, “Look, if you leave it this way, you’re not going to be eligible for any free publishing.” Authors can add as many affiliations as needed, and all of those will be checked against our deals to see if the article is eligible. Our policy is that any corresponding author affiliation on the manuscript is eligible.
Rob O’Donnell
The next slide is about the OA Switchboard. If you’re not familiar with the Switchboard, I encourage you to look into it! Not only is the functionality important to publishers, institutions, funders, and (indirectly) authors, but the organizations involved are incredibly collaborative, experimental, and working with the goal of industry-wide solutions. I’m excited that we’re now live with our Open Access Switchboard eligibility workflow, which is known as “E1” in Switchboard lingo. If a manuscript is not recognized as part of a deal using what was shown in the last step, we use the ROR IDs we’ve gathered to sequentially query each of those organizations to ask if they’ll pay the gold OA fee for the article. We do this during revision when there’s a high chance of acceptance. We don’t do it for every manuscript. That would be overkill. We’re also querying contributing author affiliations, even though we’re not collecting ROR IDs for all authors yet. This is done using smart matching (originally developed by OA Switchboard’s tech team, ELITEX, and now available open source) and that’s working well, too. Smart matching maps text-based affiliations to ROR IDs (via the ROR API) and then directs the queries to those institutions. The Switchboard also maps our tagged Funder Registry IDs to ROR and queries those organizations as well. So, we’re tagging all affiliations, all funders, and asking them, “Hey, would you be willing to pay for this?” The actual question is “Does this intended publication meet your requirements/policies? If so, will you cover the publication charges?” and each organization can reply yes or no, and cover full or partial payment of the APC. This eligibility querying workflow has the potential to facilitate funding for articles that are not covered under a Read and Publish deal.
And of course, we also use the Switchboard, via ROR tagging, to report on published articles. The “P1” workflow allows participating institutions and funders to see where and when the research from their organization or research they have funded is published by an OA switchboard-participating publisher. Data from all publishers appear in a single dashboard, with the ability to export as consistently formatted Excel or JSON.
Rob O’Donnell
And just a quick mention: we’ve recently introduced a step in our production workflow where production editors will check for any missing ROR IDs. If they find that an institution is missing from the ROR database, they request that they be added to ROR. In some cases, authors like to use a medical school or a hospital if that is where they are rather than the parent organization. And that ends up coming across production without a ROR. So Adam, I’m sorry if you’ve been getting requests for med schools.
We have, in some cases, mapped medical schools to the parent ROR ID in the EJP ROR database so that, if someone starts typing a medical school, that name is in the typeahead, but the parent ROR ID is used under the hood.
Emily is now going to talk more about what Silverchair is doing. And I’m grateful that they’re doing quite a bit! But briefly, we include ROR IDs in our JATS files, and after an article is published, Silverchair includes those IDs in Crossref deposits. As I said earlier, we also have our ROR IDs in Silverchair’s SiteManager, which checks entitlements. So the goal is to be able to report easily, via Silverchair, on Publish output and Read output for any institution.
And finally, we’re in a pilot with ResearchGate. Not all of our content is Open Access, and we are sending ResearchGate content that is access-controlled, so we need entitlement checks on the ResearchGate side. We do that via Google Scholar Subscriber Links and ROR IDs! With Anurag Acharya’s approval, Silverchair has added ROR IDs to our Subscriber Links and ResearchGate uses those to grant access to individuals from our subscribing and R&P institutions.
Amanda French
That’s amazing. That was really wonderful. I mean: all the applause. We will now hear from Emily Hazzard, Product Operations Analyst at Silverchair, about Silverchair’s part in this. Emily?
Emily Hazzard
Hi, everyone. I’ve just got the one slide, and we’re going to go into dark mode. Rob already talked about a lot of the things that we’re doing, so if there are questions, just let me know. But for those of you who I haven’t met, I’m Emily. I’m on the Product team at Silverchair. And my role is between the high-level visioning stage and the detailed requirements stage, so I’m involved in a lot of things ROR. We are mainly implementing things based on what our publishers find the most important, and we’re always open to ideas. I love persistent identifiers: I could talk about them for a long time. And that’s why we’re all here. So I’ll talk a little bit about what we currently support around ROR and a couple of things on the roadmap.
One of the things that we support is connecting institutions to ROR IDs. Publishers like Rockefeller are able to go into our SiteManager system, and then add ROR IDs to the institutional information that we store. This allows us to include ROR IDs in Google Scholar Subscriber Links, which Rob has already mentioned, and we’re going to be able to use those in other ways. Step 1 was making sure that we had the space for them in our system so that we can do everything that we want to do in the future. As you saw from that screenshot, we do currently include them in Subscriber Links, and that’s mainly being used to support the ResearchGate use case that Rob mentioned. This also means they are available to Google Scholar, but I don’t have a lot of insight as to what Google Scholar is doing with those ROR IDs now. If they choose to use them, I’m happy to share updates about that in future calls.
We also allow publishers to include ROR IDs alongside author affiliations in articles, proceedings, books, and chapters for the content that’s loaded to our publishing platform. That means that we’re able to then auto-magically downstream that information in Crossref deposits and PubMed deposits, as well as full-text deposits. Once we’ve got that information in our system, all of that information is going to be propagated out to all of those different indexing services, which is exciting. As far as things on our roadmap, in the institutional management service in SiteManager, we’re going to be introducing a way to search institutions based on the ROR ID just because it’s incredibly convenient. Sometimes it’s easier to find something based on a persistent identifier than something that might take a little bit of disambiguating (to find out how it might have been spelled or transliterated). Something else that we’re planning on doing is introducing ROR-based reporting to support those Read and Publish agreements so that we can expose the relationships between those authors and institutions, and really see what’s coming out of these institutions. Where is it published? Where does it live? And how do we serve those authors better?
So that’s what we’re doing right now. I’ve got lots of ideas for things that I am interested in. Again, talk to me if you have more questions. Are there any questions about the things that we’re currently doing or that’s on our roadmap here?
Amanda French
I suppose I’m a little curious as to whether all of the users of Silverchair get all of these features at once, or are you doing it more client by client?
Emily Hazzard
That’s a great question. So the SiteManager piece, adding ROR IDs to the institutional information, that’s available to any client right now who’s using that service. And then connecting authors to ROR IDs and including that downstream, that’s available to everyone on our latest version of the platform. We try to auto-deploy as much as we can, especially when we know it’s going to be abundantly useful for things like a persistent identifier, so that’s one of the things that I always try to make sure we can do where we can do it.
Amanda French
Wonderful. Thank you.
Emily Hazzard
Absolutely. Well, thanks, everybody. If you have any other questions, reach out.
Amanda French
Thanks for telling us all about your work with ROR, Rob and Emily.