Case Study: How and Why Optica Publishing Group Uses ROR
By Amanda French | August 23, 2024
Optica Publishing Group was one of the earliest publishers to send ROR IDs to Crossref in DOI metadata. In this interview, we speak with them to learn more about their rigorous processes for cleaning organization names.
Key quotations
“As part of discussions leading to the release of Version 2 [of JATS4R], we talked a great deal about ROR being probably the dominant identifier for affiliations in the near future.”
“We want to be good citizens of our publishing community and contribute as much metadata as possible, as much correct metadata as possible, to Crossref as an exchange mechanism among publishers.”
– Sasha Schwarzman, Content Technology Architect, Optica Publishing Group
“The messier the data, the more we need ROR.”
“ROR has been a really great tool, and it’s really helped our efforts, so we really appreciate that it exists.”
– Chris Iannicello, Director of Business and Content Intelligence, Optica Publishing Group
Amanda French
Chris and Sasha, can you tell me your names, titles, and organizations?
Chris Iannicello
Chris Iannicello, Director of Business and Content Intelligence, Optica Publishing Group.
Sasha Schwarzman
My name is Sasha Schwarzman. My position is Content Technology Architect with the Optica Publishing Group.
Amanda French
Tell us about Optica Publishing Group. When was it founded, what does it do, and what makes it unique?
Sasha Schwarzman
Optica was founded in 1916 as the Optical Society of America, and the first issue of the Journal of the Optical Society of America was published in 1917. In 2021, the organization’s name was changed to Optica to reflect the society’s global membership, and Optica Publishing Group became its publishing arm.
Chris Iannicello
The unit we work in, Optica Publishing Group, is responsible for publishing optics and photonics scientific journals and books. There’s also an outreach program that’s affiliated with the society, which is a nonprofit, and that involves hosting meetings and conferences. The society also engages with young scholars to promote the field of optics and photonics. We also get involved with legislation in Congress related to issues that affect scientific research and funding.
Amanda French
Wonderful. And how many journals and publications does Optica Publishing Group produce?
Sasha Schwarzman
Optica Publishing Group’s portfolio offers the largest peer-reviewed optics and photonics content collection. It includes 21 peer-reviewed publications, co-publications, and papers from more than 1,150 meetings and conferences, including associated videos. The content comprises more than 460,000 journal articles, conference papers, and videos.
Amanda French
Gotcha. So when did you hear about ROR for the first time?
Chris Iannicello
A few years ago, I was attempting to standardize our affiliation data a little better – clean it. And I came across GRID at that time, maybe three or four years ago. I started using GRID IDs informally in my own cleaning exercises against our affiliation data. And by affiliation data, I mean both author institutions and also institutions that subscribe to our content. Both those lists require different degrees of cleaning. Then I heard the news that GRID was being sunset, and I started learning about ROR. So about two years ago, I really started to use ROR exclusively, once I knew GRID was going away.
Sasha Schwarzman
I think I heard about the ROR system four years ago, and I believe it was at a JATS-Con conference that I attended. At JATS-Con, we always talk about persistent identifiers. When ROR came along, of course, there was an announcement, and then there was, I believe, a presentation from the ROR folks. And ever since, it has been on my radar. Then, when Crossref announced that the Funder Registry is going to be sunset, that really caught my attention. Also, I’m on the JATS4R Author and Affiliations working group. As part of discussions leading to the release of Version 2, we talked a great deal about ROR being probably the dominant identifier for affiliations in the near future.
Amanda French
Ah, yes, I’m so glad you mentioned that, because we have looked at the JATS4R proposals about affiliations during the open comment period, and they looked good to us, so we’re pleased to know that ROR is such a key part of that. I think we didn’t leave any comments, because we were just pleased with them as they were.
Sasha Schwarzman
We did retain examples with ISNI and Ringgold, because you have to include those.
Amanda French
Yes. Understandable. Chris, you mentioned that you were using first GRID and then ROR in your cleaning projects for both author affiliations and institutional subscribers. I’m curious about what that cleaning involves and why it’s important.
Chris Iannicello
The second question is a lot shorter to answer than the first, so I’m going to give the answer to the second question first, which is, the messier the data, the more we need ROR. For years, when we accepted submissions for manuscripts, which may or may not become a published article, the author could submit what institution, college, university, or laboratory they’re affiliated with. It was a free-form field, and they could put as much text as they wanted. So we have data that may mention the university in it, but it also has the address, the PO box, the phone number, and it’s one piece of metadata, it’s not split up in our database. So the value of ROR to us is just to standardize the identity of all these places. We may have hundreds of different permutations of the same institution. To me, that’s the big value: to have a way of quality checking the information we have internally.
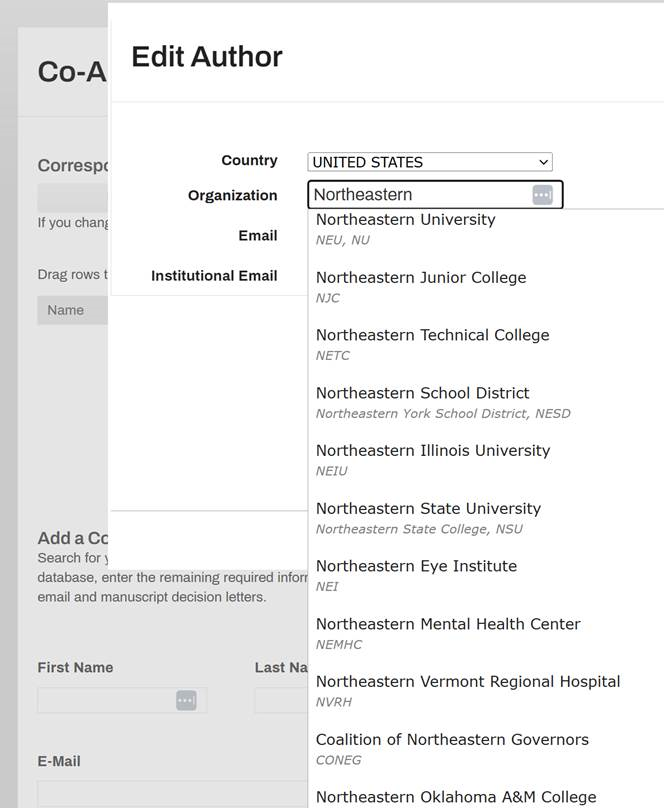
The information we’re asking for now is cleaner, because not only have we required cleaner data, but we’ve also integrated the ROR API so that authors can choose a ROR affiliation when they submit a manuscript, although not a large percentage is doing that as of yet.
ROR-powered organization pick list in Optica Publishing Group manuscript submission interface
The answer to the first question about the cleaning process is that it’s a very involved process where I take that metadata that I mentioned, which has a lot of information, and I attempt to extract the university or the laboratory or the the part of the metadata that is actually saying what the institution or affiliation is. And that is a multi-step cleaning process that has nothing to do with ROR: it just has to do with delimiting our data to the point where I can find the best possible part of the metadata of that might be an institution. Once I do that, I take that list and I put it against the ROR data. Sometimes I’ll get a one-to-one text match, and we consider that a match. If it’s not a one-to-one text match, then I run it against your API, line by line. And then I review those results manually.
Amanda French
Which is fantastic, by the way. Not everybody does that much work to get to that level of quality. I have to say, too, you’re by no means alone in having accepted affiliations as text strings for so long. I think that’s an endemic problem in publishing that for many years, even after the move to digital, people had a free-text field for that kind of data.
Chris Iannicello
When I get to the point of manual review, I have the cleaned affiliation string from our data, and the first thing I’ll do is see if there’s a URL involved, because that’s a much cleaner way to find a match, since you don’t have to worry about permutations of names and the URL changes a lot less often than the name does. If that doesn’t work, then I’ll just start Googling the name until I find something that looks like it has a ROR ID.
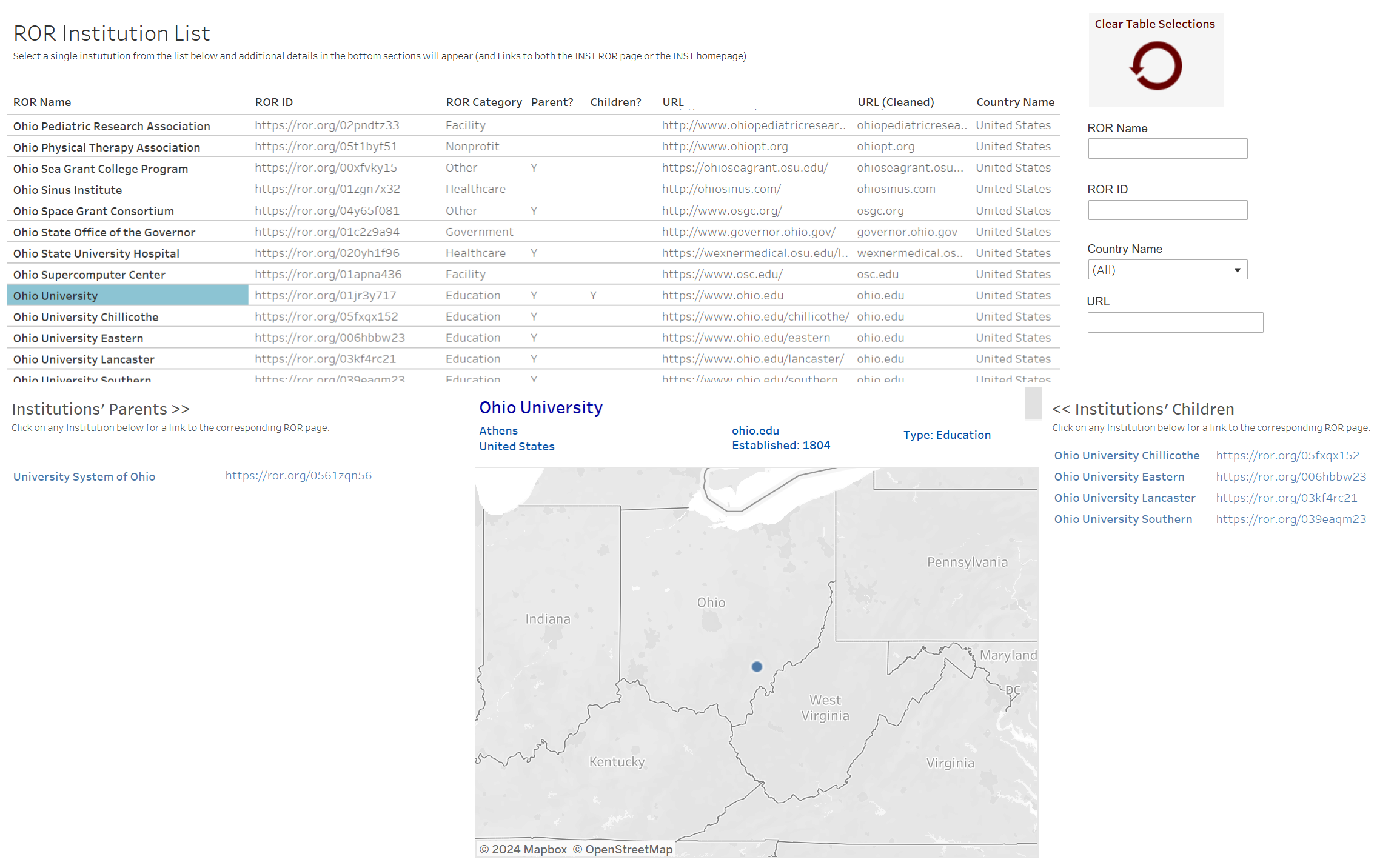
In that process, I’m searching the harvested ROR data that I have taken from your data dump, which I put into a business intelligence tool called Tableau, and I’ve included the hierarchy data, which helps. I try to run it up to the highest parent in the hierarchy chain when I assign the ROR ID or name. Sometimes I’m not able to do that, just because it’s too time-consuming and might not be granular enough anyway (for example, the “US Department of Defense” might be too broad as opposed to its children like “US Army” and “US Navy”).
Optica Publishing Group’s list of organizations and ROR IDs in Tableau.
I have a mechanism where you can see the child or the parent: you can toggle between the two, so if you want to see lower numbers, more bundled, you toggle to the parent for things like article counts and author accounts. The granularity might not be perfect, because I only have two data points, the institution I found a match for and its respective parent, no matter how many generations it is up the chain to that parent. I don’t specify that.
Once I do all that, then I can start reporting on the data and presenting it to stakeholders internally. I give them the choice between looking at the ROR ID or looking at the raw strings in the same row broken out if they ask for it, which obviously makes it a much longer report. Basically, those are the major steps.
Amanda French
I see.
Chris Iannicello
I don’t do any automated matching, because the information we’re using this for is too important. We’re not doing broad trending with this data. We’re doing reports that require very specific article counts, author affiliations, and articles per author affiliation per year. We need exact numbers or as close as we can get to it. I’ve been on the webinars where you’ve discussed automatic matching, and I’ve heard all the techniques people are using, and they’re great, and I understand why they’re doing well. But we just have to trust the data 100% for our use cases.
Amanda French
What are those use cases? In other words, what’s the purpose of your reports?
Chris Iannicello
We’re using them for prospective business arrangements. Sometimes it’s with a single university, sometimes it’s with a consortium, sometimes it’s with a whole country for Read-and-Publish deals or Publish-only deals. In those deals, when you’re discussing the details, it’s very important to know the historical counts of authors who have written articles through Optica Publishing Group, because those counts determine the basis for the amount of the deal.
If you’re not far along in the negotiation process, you may just want an order of magnitude, so you can do a quick keyword search of affiliations that may have more than one name. Now that might be done against ROR data, or that might be done against our clean affiliation data, or it might be both. That’s more informal. But when you get closer to finalizing a deal, then the exact counts become important.
But we also want to apply ROR against our internal customer data, against all of the Optica society members, all of whom have affiliation data. If we take a cross-section of all our members, what are the ten leading affiliations that they’re from? I’ve run the ROR API against those lists, and I’ve taken fuzzy matches on that, and in the reports I’ve specified that these are fuzzy. Maybe one-tenth of them are clean. I’ve set up the reports so you can toggle between the fuzzy matches and the clean matches, so you can remove the fuzzy matches from the report completely, and then you’re only looking at the ones that I manually checked. It’s a toggle that says, “manually checked” or “fuzzy match.” And I uncheck the fuzzy match by default, because I know it’s risky to report that. So, if they just want to see general trends, they can include fuzzy matches.
A related use case for that data is to try to identify organizations that have a lot of authors who publish articles with us but do not subscribe to our content.
Amanda French
That’s a great use case, of course, because it’s not even just a business opportunity, like “Hey, maybe you should subscribe.” That’s good for research, because if those researchers are publishing in your journals, then they probably want to be reading them as well.
Chris Iannicello
Yes, that’s the whole sales pitch. Researchers from your institution have published thirty articles in the past two years in our journals, but if they go to read them in your libraries, they can’t get to them, or at least not to the non-open-access ones, anyway.
Amanda French
Right.
Sasha Schwarzman
I want to elaborate on one of the use cases that Chris mentioned, which is the case where we already use ROR IDs for funding purposes. Specifically, as far as open access is concerned, there are two business models. Either it’s a funder who pays for open access, or it is an institution that pays for open access. When the institution pays, there are two variations. The first is a Read-and-Publish deal with a library consortium or with a particular institution that pays for open access. The second variation is a Publish-only deal, which can apply to open-access and hybrid journals.
Because, in both cases, it is an institution rather than a funder that pays for open access, it is crucial to identify the institution correctly, and we use ROR IDs to do so. We have already implemented that, and thanks to Chris’s efforts, we have very strict one-to-one correspondence between an institution and a ROR ID. If the ROR ID belongs to a particular Read-and-Publish deal, we send the information to RightsLink, a Copyright Clearance Center service. They clear it with the institution, and then the publisher gets paid.
As part of the extensive quality control that each journal article undergoes, I use Schematron to check the correspondence between an eligible affiliation and its ROR ID. If they don’t match, there is a QC option to reconcile them based on the ROR Registry. That is an actual use case where we already use ROR IDs for those Read-and-Publish or Publish-only deals.
Of course, as Chris said, we can use this data to know which institutions have published with us but haven’t signed a deal with us yet. Or maybe the deal needs to be renegotiated because we’re paid for this number of authors, but many more have published with us, so maybe we need to renegotiate the terms. That is very important from the business point of view.
Amanda French
Yes. I’m curious about RightsLink. Do they accept ROR IDs as an input, or do they only accept names?
Chris Iannicello
Both. We can specify three different identifier types to verify if an accepted manuscript is a match on the RightsLink side. It’s the name, the ROR ID, or the email domain. Or more than one if needed.
Amanda French
Interesting!
Chris Iannicello
We’re giving them the ROR ID and the ROR name. If there’s a submitted manuscript that comes in from a region that we may have a deal with, where the author didn’t choose a ROR value when they submitted, then I get an alert. And I’ll go and manually match it, which I can do in our internal production system. It happens pretty often.
Now, that doesn’t mean they’re part of the deal, but they’re from an area where they might be. I have configured the system to get alerts for certain areas, and, worst-case scenario, they are not part of the deal, and now we just have one more matched ROR in our data. And if I had more time, I’d go to every single paper that wasn’t matched and do that, but that’s not on my radar right now. We certainly could do that, because the ROR API is very helpful in that regard with the autofill and the drop down, and now we have the related organizations, so it’s really a very useful tool just for matching purposes.
Amanda French
That’s great. The other thing that I’m really curious about, and I don’t know if you know this, but Optica Publishing Group is one of the top contributors of ROR IDs in DOI metadata to Crossref. We haven’t yet talked about the fact that you’re doing that, that you’re making sure to include author affiliations with ROR IDs in Crossref metadata. Can you tell me a little bit more about why and how you do that?
As far as “why” is concerned, it’s because of the culture of the OPG in general, and my responsibility in particular, is to ensure that all the metadata has integrity and quality. We want to be good citizens of our publishing community and contribute as much metadata as possible, as much correct metadata as possible, to Crossref as an exchange mechanism among publishers. We try to be as accurate as possible, and we don’t see why we wouldn’t contribute this data, since it goes through the rigorous quality control that Chris has described and through other processes to make sure our persistent identifiers are correct.
As far as “how,” we have a process called fulfillment. Our colleague Jennifer Mayfield ensures that all metadata that goes to Crossref is correct. If there are any problems, Crossref reports them, and then we redeposit our metadata so that everything is accurate.
Yes, definitely. We use a subset of JATS and then transform it to the XML that Crossref accepts.
Amanda French
What’s next for you with ROR? I think you’re working on cleaning up your funder data and matching that to ROR IDs?
Sasha Schwarzman
I’ll start by explaining what we currently do, which will help clarify what we need to do moving forward and how ROR IDs will factor into that. We currently use the Open Funder Registry to assign DOIs to funders. We go through the registry from top to bottom, categorizing funders into three main groups: those requiring a CC BY license, those participating in CHORUS, and the frequent funders of optics and photonics research. Our goal is to ensure we’re capturing all relevant funders.
We maintain a list of top ancestors in each category, and this list evolves over time. For instance, we might learn that a funder now requires a CC BY license or there is a new CHORUS participant. The license information varies depending on these three categories. Each funder has descendants, sometimes quite a few. If an ancestor requires a CC BY license, then all its descendants do, too. So, each time a new release of the Open Funder Registry comes out, we go through the registry to find all the descendants in each category. Some funders are particularly dynamic. For example, the United States Department of Defense has frequent changes, and in the United Kingdom, certain funders in the CC BY category also change often.
We use Schematron technology, where we say, “All right, we found this funder.” We’ve integrated the Open Funder Registry widget into our submission system, so the XML data usually includes the funder DOI. However, sometimes, an author can’t find a match for a funder and types something in that’s not quite correct. Or, during production, an author may realize they forgot a funder and then provide its name but not the DOI. In these cases, using Schematron, we ensure that the funder’s name matches its DOI. If there’s no match, we prompt the user with the most likely DOI, using “preferred label,” that is, the official name of the funder. This step is critical because it’s important to have the correct license, like a CC BY license, or to know if it’s a CHORUS funder, which may affect the embargo period and so on.
Now, with the news that the Open Funder Registry will sunset and be replaced by the ROR Registry, my focus in the coming months will be figuring out how to replicate or redesign this process to maintain the quality control we need. The first question is about coverage. Thanks to Chris, we have many years’ worth of data on all the funders of research published in our journals. Are they all in the ROR Registry? We’ve been working with you to identify any missing ones because we can’t switch until the ROR Registry covers a significant portion of what we have.
We also need to figure out how to manage this process. How do we find those descendants? What tools do we need? Should we use the ROR API or the data dumps, which I imagine will be similar to the Open Funder Registry releases? These are very different data sources. In the coming months, I’ll be exploring the ROR Registry to determine whether to use the API or the data dumps and how to recreate or maybe even invent new processes that give us the same level of control we currently have with the Funder Registry.
Amanda French
Oh, that’s exactly what I wanted to hear. We’re hoping to work quite closely with you to make sure that all of the funders that you need to have in ROR are in ROR, assuming they’re in scope. We’ve had some correspondence with Chris about this already.
The last I checked, about 54% of Funder Registry records have equivalents in ROR, and those are the most frequently used funders. We’re continuing to go down the list of less frequently used funders and updating ROR to include them when possible.
We’ve been talking with CHORUS, as well, and they are also in the process of building ROR into their workflows. They’ve got it in some of their services and in their public API. And on the recent Crossref community call, Crossref emphasized that they’re prioritizing accepting ROR IDs in the schema where they currently accept Funder IDs.
Sasha Schwarzman
By the way, this is in Chris’s purview, but we have years and years and years of data about funding based on the DOIs of those funders, and then when we switch, there will be years and years of data based on ROR. And I wonder if we need to have business intelligence covering the range of years whether we will have to account for two identifiers for the same funder, which may or may not be a challenge.
Chris Iannicello
I’m not sure. I mean, it’s pretty straightforward to look for one and then the other if the first one was missing. But as far as my part in this effort, we have about 13,000 different funder names, and maybe half of them have a DOI. And we’re focusing on the ones that have a DOI for now, and of those 6000 or so that have a DOI, I’ve matched about 4500 of them. Most of them were not matched manually: I was able to find a match through the DOI in ROR through an automatic name match. I was only able to manually match a couple hundred of those so far, but I haven’t spent a lot of time on that part of it yet. The remaining 1400 or so I will probably match manually through the year. And the ones that don’t have a DOI we may never match, as it’s just very time-consuming to match it that way. Maybe we’d apply a fuzzy match to it, if someone requests some kind of high-level reporting.
Amanda French
Also, we are working on an additional service to match names to ROR IDs. We’re doing that in conjunction with Crossref. Our API, as you’ve mentioned, Chris, does do a good job of matching, but we’re looking at developing a matching service that will do an even better job of that.
One question I’d love to ask, and we’ve touched on this already: What do you hope ROR does in the future? What problems could we fix for you, or what changes could we make that would make your lives easier?
Chris Iannicello
Any type of improvement for matching would be great. Perhaps a mechanism to take in verified matches from me and others to use as training data for some kind of machine learning tool. We’ve dabbled in that a little bit, internally, and the results were not good, so it may be a non-starter. I’m assuming that it won’t be a non-starter forever; if the AI is not up for the challenge now, I’m sure it will be soon enough. That might be something to pursue down the line, because I can provide about 5,000 manually matched records. There might be a mistake in there, but I’ve looked at each one. It could be a basis for all kinds of matching down the line, perhaps.
Amanda French
No, I think you’re really right. We have done some of that with the American Physical Society. They also did a lot of heavy curation where you can be really sure that this particular variant of this name matches this ROR ID. We have a GitHub repository where we store both the code and the data for that matching service that I mentioned, and in the test_data folder, there are some datasets. The APS dataset has some verified matches that they have manually curated in the same way that you do. The Crossref publisher assertions are from the Crossref API where the publisher has asserted that this name matches this ROR ID. We think that’s probably less reliable than one that was manually reviewed by the publisher. I’ll have to see if we could use some additional datasets for that project or if it’s too far along.
Chris Iannicello
Sounds good.
Sasha Schwarzman
One particular challenge is dealing with Chinese funders. Funders there change rather frequently, and because of translation challenges it’s not always clear whether the author specified the official funder’s name and what funder that is. That is, I think, a particular challenge in dealing with Chinese funders.
Amanda French
Yes, that’s been a priority for us. As you know, in our March community call we had a presentation from Jackson Huang, who was a LEADING Fellow with us and is now a member of our Curation Board, and who is a Chinese speaker who’s done some work on that. The focus wasn’t specifically on funders; but more like Chinese-language organizations in ROR generally.
What else would you like to say about ROR, or about the Optica Publishing Group, or about metadata, or about anything at all?
Chris Iannicello
I don’t have anything else other than it’s been a really great tool, and it’s really helped our efforts, so we really appreciate that it exists.
Sasha Schwarzman
I’m looking forward to unifying the IDs for the funders and affiliations. It does make sense. I realize it will be challenging, but in the long run, I think it’s the right thing to do, especially because the ROR Registry is actively and openly curated and has an active user base. So I am looking forward to this development and to this challenge.
Amanda French
Wonderful. Yes. I’m glad to hear that. I think it’s going to be very exciting to see everything that comes out of this. Thank you both for taking the time to talk to me.
Chris Iannicello
And we thank you so much.
Sasha Schwarzman
Thank you very much!
Questions? Want to be featured in a ROR case study? Contact community@ror.org.