In this interview with Curvenote cofounder Rowan Cockett, we envision a world in which an authoring and publication platform helps scientists collaborate earlier, publish faster, and easily use structured metadata to create fully connected and highly interactive publications and portfolios.
Key quotations
“This represents the ideal of a scholarly ecosystem that is rich with APIs and structured data, and our authoring tools need to be able to show the value of that as you’re working. You see a paper, you copy the DOI, and then you don’t have to think about the references, you don’t have to think about APA formatting. You see a ROR, you copy it into your document, and then it turns into the name of the organization with all of the information directly available in a hover reference.”
“It took less than 45 minutes [to integrate ROR], and then we were up and going.”
“We can work and share and do that as fast as possible and that can be supported by the scientific and scholarly infrastructure as well. And that again includes DOIs, and ORCID, and ROR, and things like that. I think it’s an exciting vision, and it’s happening.”
– Rowan Cockett, Cofounder and CEO, Curvenote
Amanda French
Thanks for speaking with us. Tell us about Curvenote.
Rowan Cockett
Curvenote’s mission is to free science from static PDF documents to enable researchers to continuously share more interactive, reproducible, and richly-linked scientific content. Curvenote develops authoring and publishing tools for researchers, societies, and institutes, with a focus on computational research. We build authoring tools, including a “What You See Is What You Get” (WYSIWYG) editor, with the goal of making both the way that science is authored and the way that science is published a lot easier. We’re also thinking about how scientific metadata is included, trying to make sure that scientific publications are born with metadata all the way through.
We’ve done some really exciting integrations with ROR, as well as with ORCIDs and DOIs and RRIDs. For instance, one thing we’re thinking about is that as authors are writing, instead of having a citation manager where you’re copying the name and the title and the year into your text as a text-only citation, you just copy in the persistent identifier and then it automatically queries all of the scholarly databases against that citation for you. And then you get a very beautiful site that you can publish out of that. I use the word “site” rather than “journal article,” because I think one of the things that is difficult for scientists to do is to have a portfolio of their work. When you’re using the publishing ecosystem, your work is scattered all around the place. It’s really difficult to show all of the papers and articles and blog posts all in one collection on a landing page on your website.
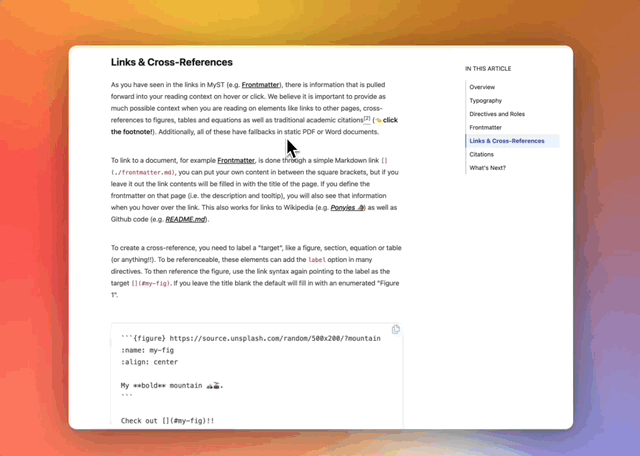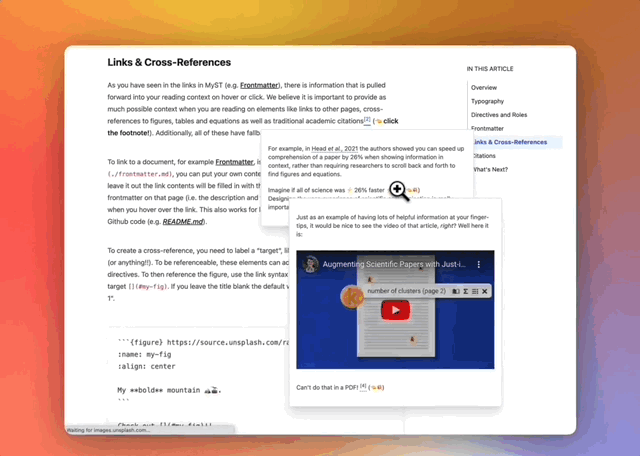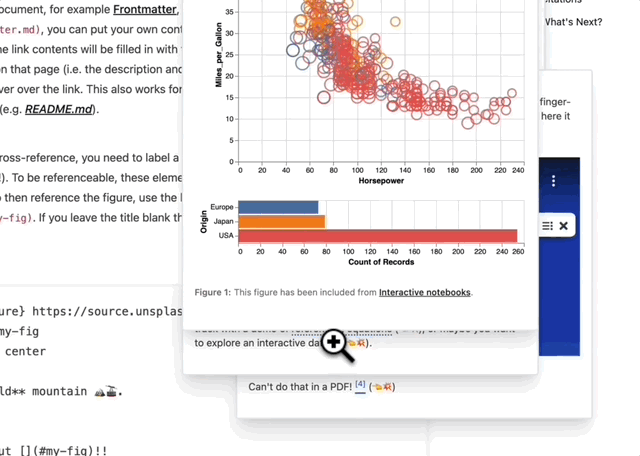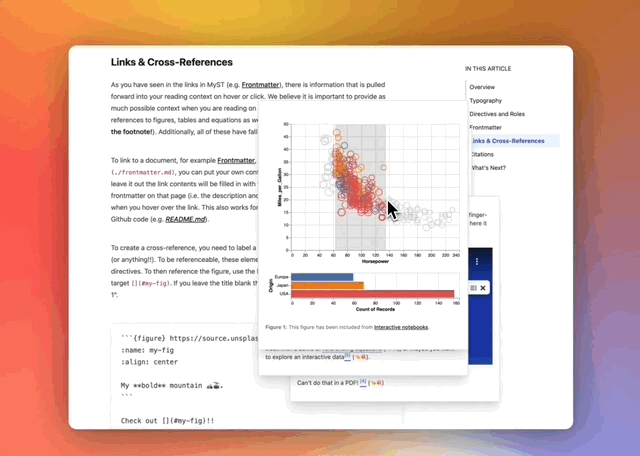
We’re also elevating a lot of scientific computational work by letting people show off interactive Jupyter Notebooks. I think by bringing all this a little bit closer together and into the scientist’s control, you can experiment a lot more with how you’re presenting your work. You can push on things like reproducibility and interactive apps that are educational rather than focusing only on novelty in the scientific paper sense. What we’re trying to make possible is the ability to continually update that project, that paper, that article, that blog post, and to make sure there’s good metadata throughout that entire process such that it’s actually integrated into the scholarly ecosystem.
Demonstration of richly-linked and interactive scientific content in Curvenote.
Amanda French
Would it be fair to say that Curvenote is a digital-first platform?
Rowan Cockett
Oh, yes. It creates beautiful PDF documents, but that is not the point.
Amanda French
Does this come out of your own scientific training?
Rowan Cockett
Yes. I have a background in Geoscience. I started creating interactive visualization tools for my peers in undergrad and understood that the web is just an exciting platform on which to disseminate these things. I saw my peers tinkering with geologic models and seeing the results right away, and there was this really close interactivity loop where they could discover things just by using those models. That was something that I learned in undergrad. I started and then sold a company around that over the next few years. Then I was working at that acquiring company for about four years, working in large-scale version control system collaboration for environmental science, civil engineering, and mining companies, and creating platforms for those companies. I was in charge of a large team over there.
While I was doing that, I was also doing my PhD in Computational Geophysics, so lots of open source technology, lots of Python, and lots of Jupyter. We were deploying courses that use those interactively in the classroom, and we took those on lecture tours. So we saw how powerful it was to put research tools directly in the hands of students all over the world, and rather than giving them a PDF with a picture of something, you give them a direct connection to the computation. With a PDF, there are no avenues back to where this came from. The actual scientific work behind that PDF document is all just lost. That was a really eye-opening experience of integrating reproducible science and open source communities into the medium that you’re using to communicate.
And while I’m doing that, I’m also going through scientific publishing and, like, getting my PDF paper rejected from multiple journals. Just honestly the worst.
Amanda French
And how long did it take to get those rejections?
Rowan Cockett
I was running a 65-person team at the same time as I was trying to finish my PhD, and I was in spurts of trying to get my PhD over the line, so it took three years for me to publish that paper. And the most disappointing thing is that at the end of those three years, someone reached out with a dataset that could use my work. That was the first time that had happened, and we completely missed out on the collaboration possibilities. If I had published right away and got that out there, I could have collaborated with that person at the start and made a much bigger impact.
My research would have been much more applicable with a field data set. I was doing theoretical modeling, and I did the first 3d model and inversion of a vadose zone dataset of infiltrating water in an agricultural setting. And that was all theoretical and computational: I demonstrated that this was possible, but not in a field sense. I didn’t actually go and apply it anywhere. But there are people who are collecting data that I could work with, and because of the scientific publishing ecosystem, I had zero capability to work with those people, and I think it limited the impact of that research project. By the time the research was published, I was no longer working on that project, and I think that’s just a shame, honestly.
I started Curvenote with the idea that you need that direct connection between research and publishing — working and sharing. That experience I described taught me that you need to be able to get your work out there and you need to get feedback right away. It needs to be born on the web with metadata right from the start. I think most scientists do their writing in Word documents, so that was the experience that we were going after for Curvenote: a What You See Is What You Get text editor that integrates with computation and metadata in a much richer way.
With the computation aspects, I think what I underestimated was that the communities who work in Python and Jupyter are much more used to text markup than to working in WYSIWYG editors. There are ways to work across those spectrums, but to enable that reproducibility, we needed to move into that text markup space. So we joined the Executable Books project, we open sourced all of Curvenote’s command line tools, and that was the start of the MyST-MD project, which is growing and helping the Jupyter Book ecosystem to create tutorials and educational materials. The MyST-MD project has recently become part of the Jupyter Books project officially, which is really exciting. Jupyter won the Open Science Award from the White House in the spring, and it’s making significant Open Science progress. We are bringing science communication tools to the core of Jupyter and integrating those metadata tools into the fabric of the Jupyter ecosystem.
Amanda French
That’s fascinating. I didn’t realize all the connections to Jupyter.
Rowan Cockett
Yeah, we’ve been working very hard.
Amanda French
How does Curvenote address the concept of peer review?
Rowan Cockett
There are different ways to publish MyST sites. We have a publishing system for Curvenote, so you can publish something yourself and just post it (for example to GitHub pages), but if you want a DOI on that, if you want to incorporate it into a scientific journal and have some of these better integrations into the scholarly system that are archival and that involve peer review, for example, that needs a system around it. And yes, the Curvenote publishing system and platform enables the creation of peer-reviewed journals. We’re working with AGU, the American Geophysical Union, which is a large-scale publisher. They’re thinking about how to do these web-first papers, these computational articles, and they’re experimenting with that and running that on the Curvenote platform. And that’s the same thing we’re doing with the Microscopy Society of America, which was just presented in Nature Magazine.
Amanda French
Got it.
Rowan Cockett
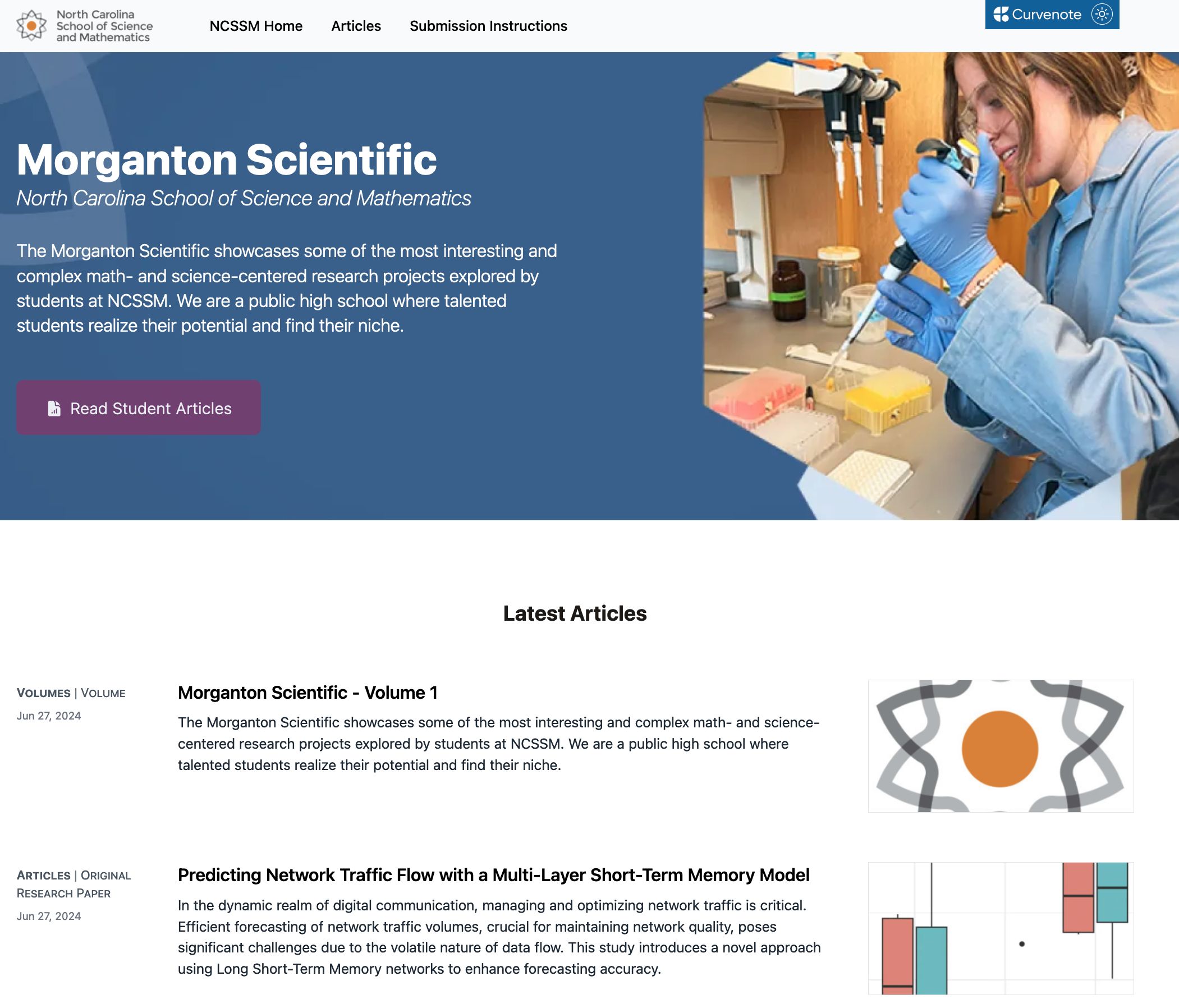
The North Carolina School of Science and Mathematics is also using Curvenote – that’s high school students learning about ORCIDs, RORs, and DOIs for the first time! There’s a teacher there who wanted his students to be able to have a breath of fresh air in the science ecosystem and to learn what it would be like for them to publish in six years. And that means they’re publishing immediately. They’re getting DOIs, they have ORCIDs, they have a ROR! Their work is born open access, and it’s born with reproducibility, and it’s born with the datasets integrated. It’s just so cool. Their journal is called The Morganton Scientific.
NCSSM showcases student research in Curvenote-powered The Morganton Scientific.
Amanda French
Very cool! There’s so many people experimenting right now with new publishing models, new peer review models, new models of open preprint dissemination, that kind of thing. And it’s so clear that it’s a generational type of thing. I don’t think younger people coming into science have the patience for the kind of print-first model that persists, which has just been replaced with a PDF in place of print.
Rowan Cockett
Yes, exactly. And that’s the way that we’re framing Curvenote, as a next-generation tool, a platform where scientific computation, scientific reproducibility, and scientific metadata are deeply integrated. And what does “next generation” mean? It means that it’s easy enough for a high school to get up and running and host their own journal! They can do that by themselves, and it’s open access, and it’s better than most journals out there. I think that it’s just exciting. Eighteen-year-olds can do this, so there’s no excuse!
Amanda French
Tell us about how you’re using ROR now and how you might intend to use it in the future.
Rowan Cockett
There are a couple of different ways. There are the ROR IDs in affiliation metadata that we’re collecting, so inside of Curvenote, you can add your ROR ID in the metadata, and that’s collected along with your affiliation. And then we have just started integrating that into the MyST ecosystem, so now, when you paste a link to ROR, you can hover over that anywhere in your document, and you can see the integrated metadata.
In Curvenote, hovering over the text ‘University of British Columbia’ brings up information about the organization from ROR.
And again, this represents the ideal of a scholarly ecosystem that is rich with APIs and structured data, and our authoring tools need to be able to show the value of that as you’re working. You see a paper, you copy the DOI, and then you don’t have to think about the references, you don’t have to think about APA formatting. You see a ROR, you copy it into your document, and then it turns into the name of the organization with all of the information directly available in a hover reference.
Amanda French
Cool. And do you have a model for funding information in Curvenote?
Rowan Cockett
We rely on the same funding-statement standards that we have developed into the MyST ecosystem. Part of the work we’ve been doing with the Sloan Foundation and with AGU was collecting the funding information and making sure that that’s easy to author in a YAML-based format. That’s something that is presentable to authors, so that they can write their funding information in with a couple of DOIs. We focused on the Crossref Funder ID as the main integration point there.
Amanda French
Right. That is currently the standard for a funder identifier. I don’t know whether you saw that Crossref did announce last year that over the long term ROR will be the standard for identifying funders as well as other research organizations. We’re in the process of doing a lot of curation in ROR to make sure that all the funders are represented, and Crossref is working to make sure that ROR IDs can be accepted as funder identifiers in the Crossref schema. So just be aware that that’s coming. [See our Funder Registry transition guide for more information.]
Rowan Cockett
We will make those changes. That’s good to know.
Amanda French
MyST is a flavor of Markdown, correct? How is it different from regular Markdown?
Rowan Cockett
Yes, it is a flavor of Markdown. We’re pretty loose in the way that we talk about the MyST ecosystem, because there’s really three parts of it. First, there’s the flavor of Markdown – the actual syntax that you write and see. Second, there is the structure of that after it has been parsed. That piece is much more similar to JATS – there’s basically a one to one mapping of that next-generation scholarly structured data to what is in JATS XML today. There’s a MyST spec describing the structure of these documents, which we’re working on in the MyST community. Third, there are the command line tools, which make it very, very easy to get up and going. So MyST is more than the markup language: again, you paste a DOI in there and it pulls in the references, it talks to various external services, and MyST brings that authoring experience fully together.
Amanda French
Great. Thanks for that.
Rowan Cockett
Currently, there’s 15% adoption of the MyST language in the scientific documentation community, and that’s actually quite large.
Amanda French
That’s quite good, yes!
Rowan Cockett
That’s active documentation for projects, and there’s a couple of caveats in there, but that’s 15% right now. We’re working with the Python community to bring them over into this MyST ecosystem. That’s one of the entry points to a large part of the scientific computation ecosystem: teaching people how to author in this markup language, providing metadata in a structured way, and then coming all the way back. Over the coming years, MyST will be a default language in the Jupyter ecosystem that’s available. We’re starting to integrate MyST into the fabric of how scientists are authoring computational documents and computational articles.
Amanda French
It’s very smart to connect to things like Jupyter – tools that people use all the time. At one point, Jupyter was probably itself just a tool that nobody knew about, just used by a few different people. And then it was everywhere, and it became something everyone was using all the time, because it filled a need.
Rowan Cockett
Yeah. There’s a great TED talk called “How to Start a Movement.” It’s a dance party. The take-home there is that you need to join the things that are already existing and put your effort behind them. It takes a different kind of leadership to join these movements rather than start your own thing.
This is very much our approach, to reinforce existing communities, to bring new experiences to life inside of those and be that strengthening and connecting tissue. I think that’s somewhat lacking in how scientists experience the scholarly ecosystem in their day to day work. They have DOIs, they use Google Scholar, they see the list of papers that cite them, but they don’t have that direct connection to adding metadata in the way that they should. It should be tangible. They should get a hit of dopamine.
Amanda French
The UI you’ve made is actually really fabulous, because you can see the metadata, right? You can see all the connections underneath. People who don’t code or people who don’t really work with a lot of metadata often have a hard time understanding the importance of persistent identifiers. I think it helps when people can see, visually, that the identifier is connected to this knot of information.
Rowan Cockett
Right.
Amanda French
How was ROR to integrate, technically? Was it difficult?
Rowan Cockett
It took less than 45 minutes, and then we were up and going.
Amanda French
Amazing. That’s great to hear. What else would you like to say about ROR or about your work?
Rowan Cockett
The next few years in scientific publishing are going to look very different. I think there’s a wave that’s been building up over this time. We’ve been working for five years on Curvenote, MyST and the underlying authoring tools, and the scientific publishing ecosystem and the players in that space don’t see that coming, because they’re not really paying attention to educational tutorials that people are publishing by themselves, or blog posts that are using this, or scientific documentation.
This is where people are doing their work. That’s where people work every single day. And if we are extending the publishing ecosystem out from that, and deeply integrating it into the fabric of how people are working daily, that is a very different future than how we think about scientific publishing today. It’s much more about science communication. How are you getting feedback as fast as possible? How are you directing micro-expertise? How are you thinking about how to integrate with services like PREreview to bring that attention closer to when you’re doing a statistical analysis? You can get your figure out in front of people. You can get your methods section out in front of people.
And that’s a possibility that is being enabled by these various communities working together. That is a radically different reimagining of how the science infrastructure is supporting the work and communication of scientists. It can help support today’s publishing infrastructure, but it doesn’t have to just be that. We can work and share and do that as fast as possible and that can be supported by the scientific and scholarly infrastructure as well. And that again includes DOIs, and ORCID, and ROR, and things like that. I think it’s an exciting vision, and it’s happening.